-
Google Cloud Speech API 개념및 기능 설명CS/졸업 프로젝트(Duk to Me) 2023. 6. 19. 19:34반응형

https://hypemarc.com/gcp-google-speech-to-text/ Google Cloud Speech API는 Google의 머신러닝 신경망 기술을 활용하여 음성을 텍스트로 또는 텍스트를 음성으로 변환하는 기능을 제공한다. 딥러닝 알고리즘을 사용하여 다양한 음성 언어와 방언을 지원하며, 대량의 음성 데이터를 학습하여 높은 정확도를 제공한다. 또한, 간단한 API 호출을 통해 손쉽게 음성 처리 기능을 구현할 수 있어 다양한 음성 기반 애플리케이션 개발에 활용할 수 있다.
ⓐ Speech-to-Text (https://cloud.google.com/speech-to-text?hl=ko)
Speech-to-Text API는 음성을 텍스트로 변환하는 강력하고 정확한 클라우드 기반 서비스이다. Speech-to-Text에는 음성인식을 수행하는 세가지 주요 방법이 있다.
1) 동기 인식(REST, gRPC): 1분 이하의 짧은 오디오 파일을 텍스트 처리. 오디오 데이터를 Speech-to-Text API로 보내고, 해당 데이터를 인식하고, 모든 오디오가 처리된 후 결과를 확인할 수 있다.
2) 비동기 인식(REST및 gRPC): 최대 480분 길이의 긴 오디오 파일을 텍스트 처리. 오디오 데이터를 Speech-to-Text API로 보내고, 장기 실행 작업을 시작한다. 이 작업을 사용하여 주기적으로 인식 결과를 폴링할 수 있다.
※ 폴링(polling)이란? 하나의 장치(또는 프로그램)가 충돌 회피 또는 동기화 처리 등을 목적으로 다른 장치(또는 프로그램)의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식을 말한다.
3) 스트리밍 인식(gRPC만 해당): gPRC 양방향 스트림에 제공되는 오디오 데이터를 인식한다. 스트리밍 요청은 마이크에서 라이브 오디오 캡처 용도와 같은 실시간 인식 용도로 설계되었다. 스트리밍 인식은 오디오 캡처 중에 중간 결과를 제공하므로, 사용자가 말하는 중에도 결과를 표시할 수 있다.
Speech-to-Text는 다양한 인코딩을 지원한다. 아래 표는 지원되는 오디오 코덱이 나열되어 있다.
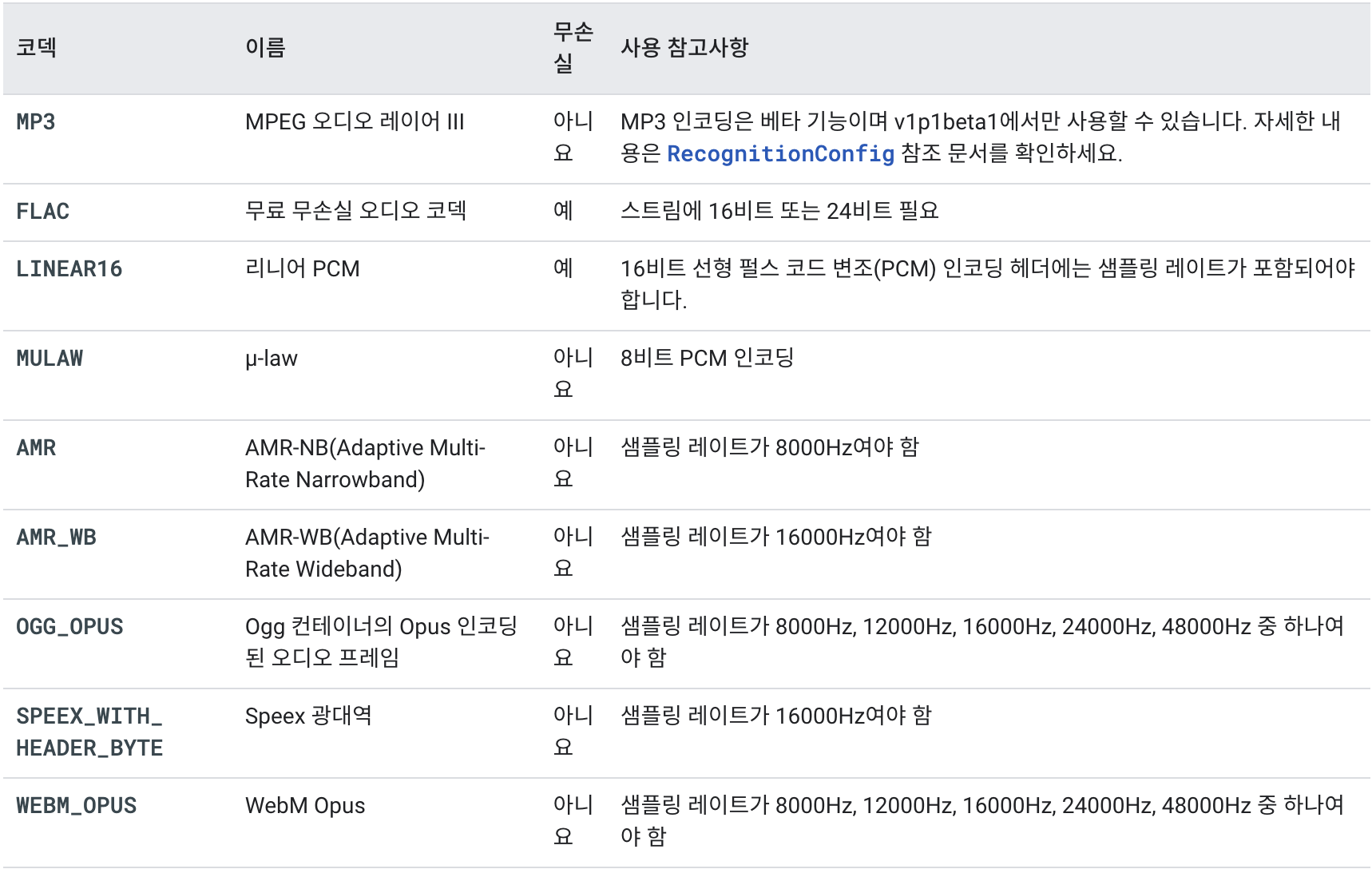
https://cloud.google.com/speech-to-text/docs/encoding?hl=ko Speech-to-Text API는 유료 서비스이며, 가격은 서비스에서 매월 성공적으로 처리된 오디오 양(1초 단위로 측적)에 따라 책정된다. API가 응답을 반환하면 요청에서 전송된 오디오가 성공적으로 처리된 것으로 간주된다. 여기에는 빈 응답도 포함된다. API가 오디오를 처리했지만 텍스트로 변환할 수 없었음을 나타낸다. 서버 오류가 발생하는 요청은 성공적으로 처리된 것으로 계산되지 않으므로 비용이 발생하지 않는다.
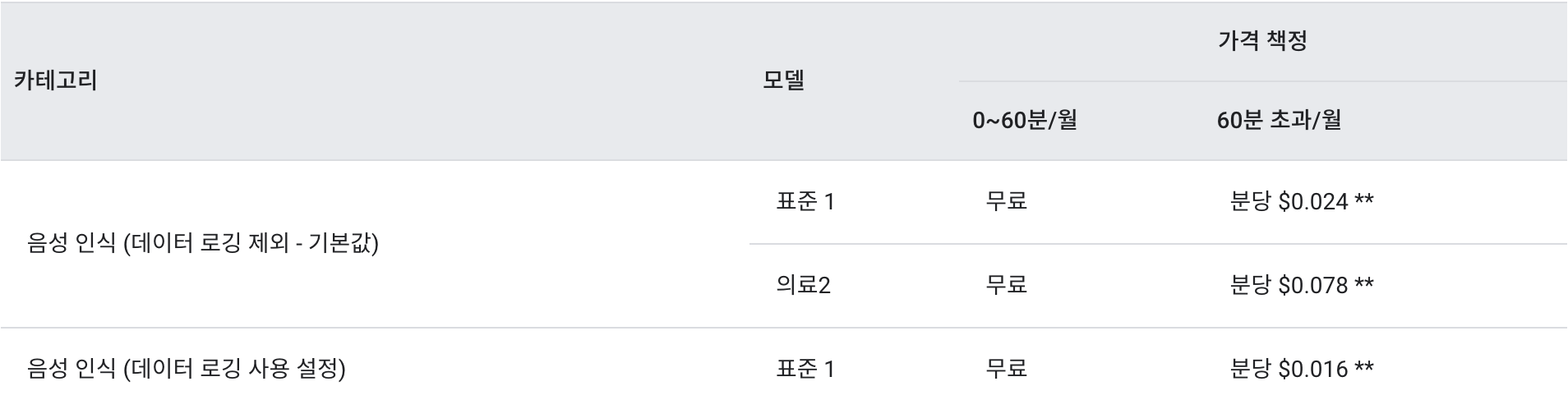
https://cloud.google.com/speech-to-text/pricing?hl=ko ⓑ Text-to-Speech (https://cloud.google.com/text-to-speech?hl=ko)
Text-to-Speech는 텍스트를 자연스러운 음성으로 변환해주는 클라우드 기반 서비스이다.
Text-to-Speech API 가격은 서비스로 전송되어 오디오로 합성되는 문자 수(영문 기준)를 기준으로 공백까지 포함하여 매월 책정된다. 사용량이 월별 무료 문자 수를 초과하면 자동으로 청구된다.
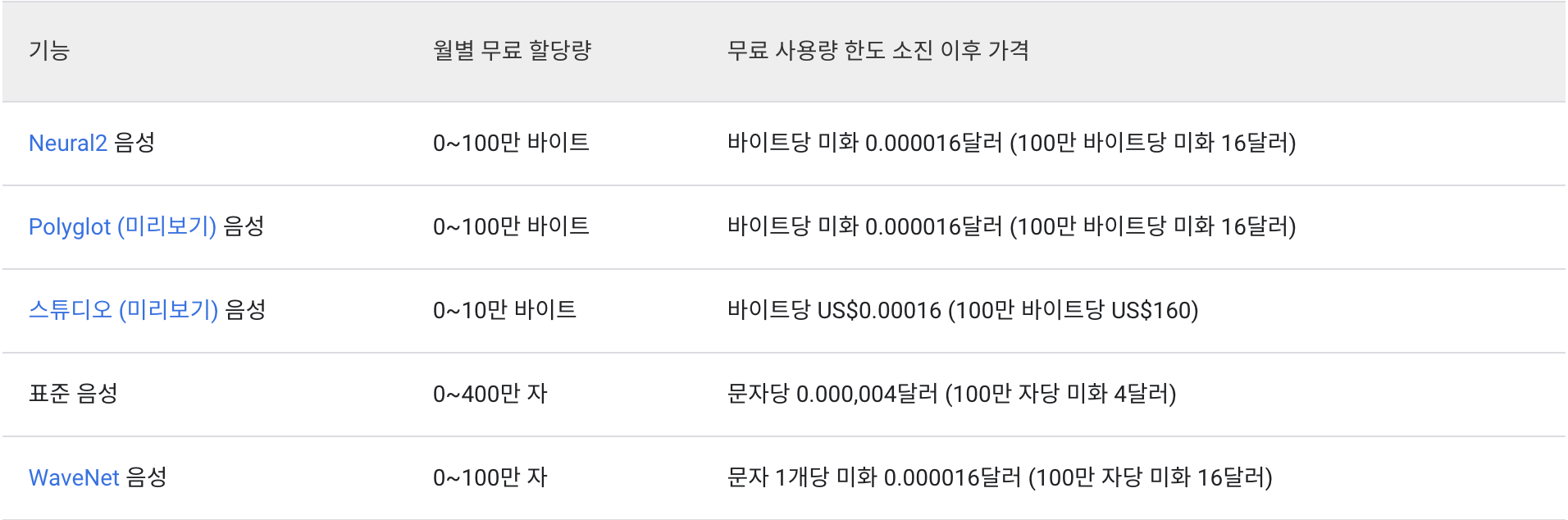
https://cloud.google.com/text-to-speech/pricing?hl=ko 반응형'CS > 졸업 프로젝트(Duk to Me)' 카테고리의 다른 글
Unity에서 여러 Scene으로부터 점수를 합산하여 내는 점수체계 C# Script 코드 쓰기 (0) 2023.08.16 [이슈관리] Unity에서 Google Speech API Asset의 C# Script 고치기 (0) 2023.06.26 [이슈관리] Google Cloud Text-to-Speech(TTS) API, 목소리 성별 바꾸기 (0) 2023.06.26 Google Cloud Text-to-Speech(TTS) API, Python으로 사용하기 (0) 2023.06.20 Google Cloud Speech-to-Text(STT) API 초기설정및 Python으로 사용하기 (0) 2023.06.20