-
[정보처리기사 필기] 알고리즘 (Algorithm)CS/정보처리기사 2023. 6. 29. 22:14반응형
¶ 알고리즘의 개념
알고리즘은 어떠한 문제를 해결하기 위한 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 기법이다.
▶ 시간 복잡도에 따른 알고리즘 분류
복잡도 설명 대표 알고리즘 O(1) - 상수형 복잡도
- 자료 크기 무관하게 항상 같은 속도로 작동
- 알고리즘 수행 시간이 입력 데이터 수와 관계없이 일정해시 함수
(Hash Function)O(log2^n) - 로그형 복잡도
- 문제를 해결하기 위한 단계의 수가 log2^n번만큼의 수행 시간을 가짐이진 탐색
(Binary Search)O(n) - 선형 복잡도
- 입력 자료를 차례로 하나씩 모두 처리
- 수행 시간이 자료 크기와 직접적 관계로 변함(정비례)순차 탐색
(Sequential Search)O(nlog2^n) - 선형 로그형 복잡도
- 문제를 해결하기 위한 단계의 수가 nlog2^n번만큼의 수행 시간을 가짐퀵 정렬, 합병 정렬(병합 정렬), 힙 정렬 O(n^2) - 제곱형 주요 처리 루프 구조가 2중인 경우
- n크기 작을 때에는 n^2이 nlog2^n보다 빠를 수 있음거품 정렬, 삽입 정렬, 선택 정렬
① 검색 알고리즘
㉮ 순차 검색 (Sequential Search)
- 순차 검색은 배열의 처음부터 끝까지 차례대로 비교하여 원하는 데이터를 찾아내는 알고리즘이다.
㉯ 이진 검색 (Binary Search)
- 이진 검색은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 알고리즘이다.
- 탐색 효율이 좋고 탐색 시간이 적게 소요된다.
- 가운데 레코드 번호를 찾기 위해서는 다음 식을 사용한다. (소수점이 나올 경우 버림 처리한다.)
이진 탐색 가운데 레코드 번호 M = [F + L / 2] F: 남은 범위 내에서 첫 번째 레코드 번호
L: 남은 범위 내에서 마지막 레코드 번호
M: 남은 범위 내에서 가운데 레코드 번호아래는 이진 검색의 구체적인 실행이 어떻게 이뤄지는지 보여준다.

https://velog.io/@ming/%EC%9D%B4%EB%B6%84%ED%83%90%EC%83%89Binary-Search ② 정렬 알고리즘
㉮ 퀵 정렬 (Quick Sort)
- 퀵 정렬은 피벗을 두고 피벗의 왼쪽에는 피벗보다 작은 값을 오른쪽에는 큰 값을 두는 과정을 반복하는 알고리즘이다.
- 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬한다.
- 퀵 정렬의 수행 시간은 다음과 같다.
최적 수행 시간 O(nlog2^n) 평균 수행 시간 O(nlog2^n) 최악 수행 시간 O(n^2) ※ 피벗이란? 특정 계산을 수행하기 위한 임의의 알고리즘에 의해 먼저 선택된 행렬의 성분.
퀵 정렬의 개념을 보여주는 이미지이다.
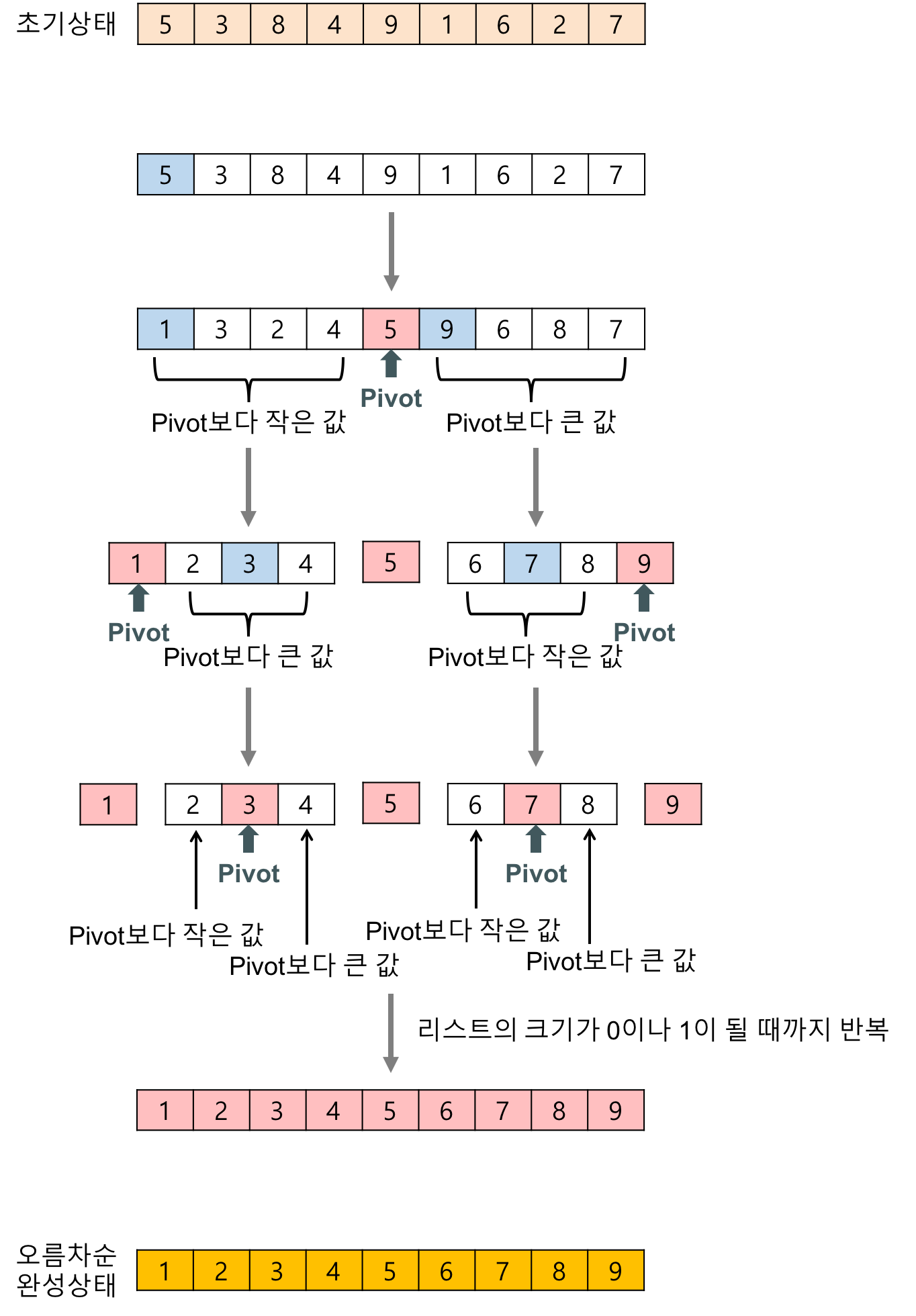
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html 아래는 퀵 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.
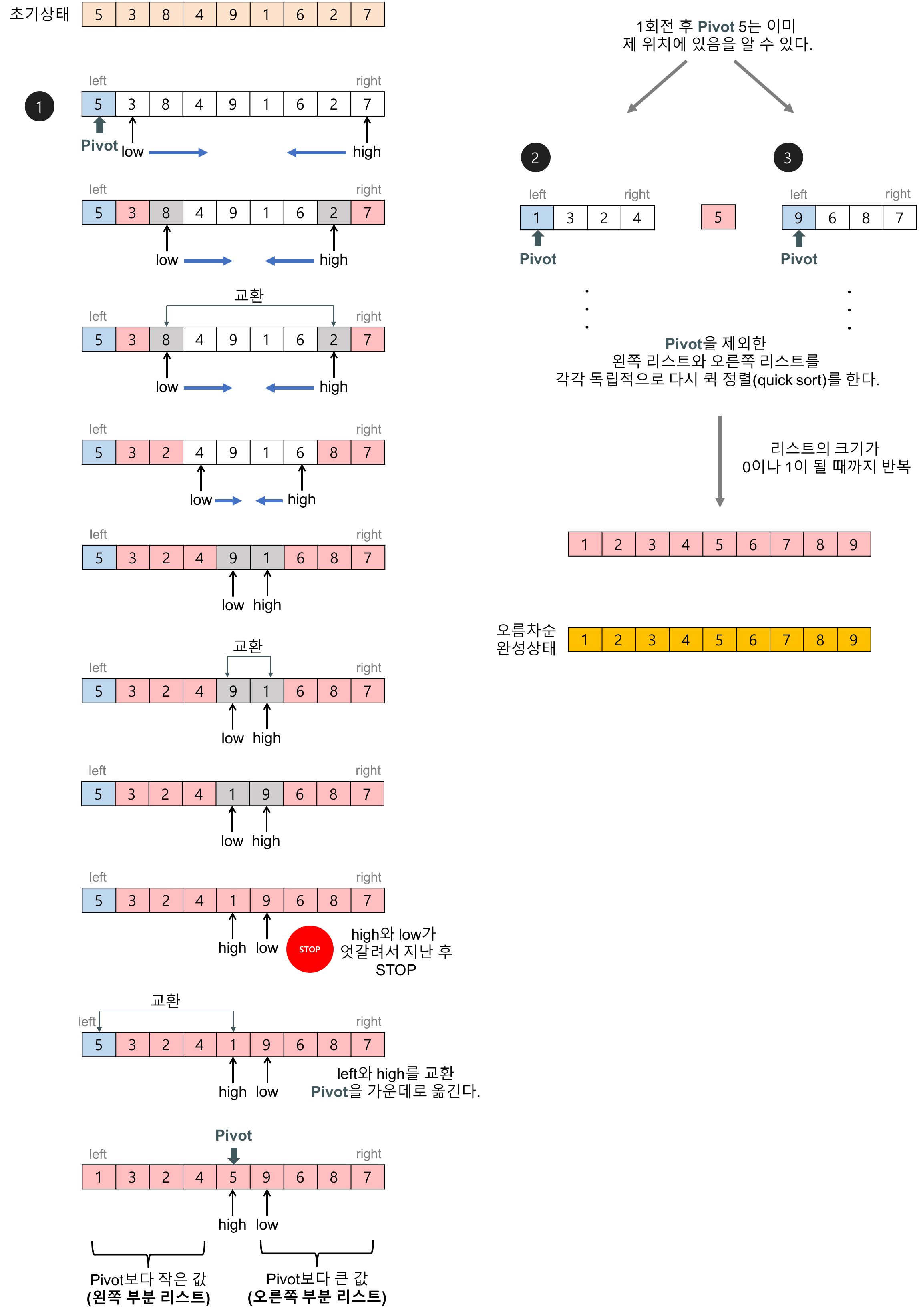
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html ㉯ 합병 정렬 (Merge Sort)
- 합병 정렬은 전체 원소를 하나의 단위로 분할한 후 분할한 원소를 다시 합병해서 정렬하는 알고리즘이다.
- 합병 정렬의 수행 시간은 다음과 같다.
최적 수행 시간 O(nlog2^n) 평균 수행 시간 O(nlog2^n) 최악 수행 시간 O(nlog2^n) 합병 정렬의 개념을 보여주는 이미지이다.

https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html 아래는 합병 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.
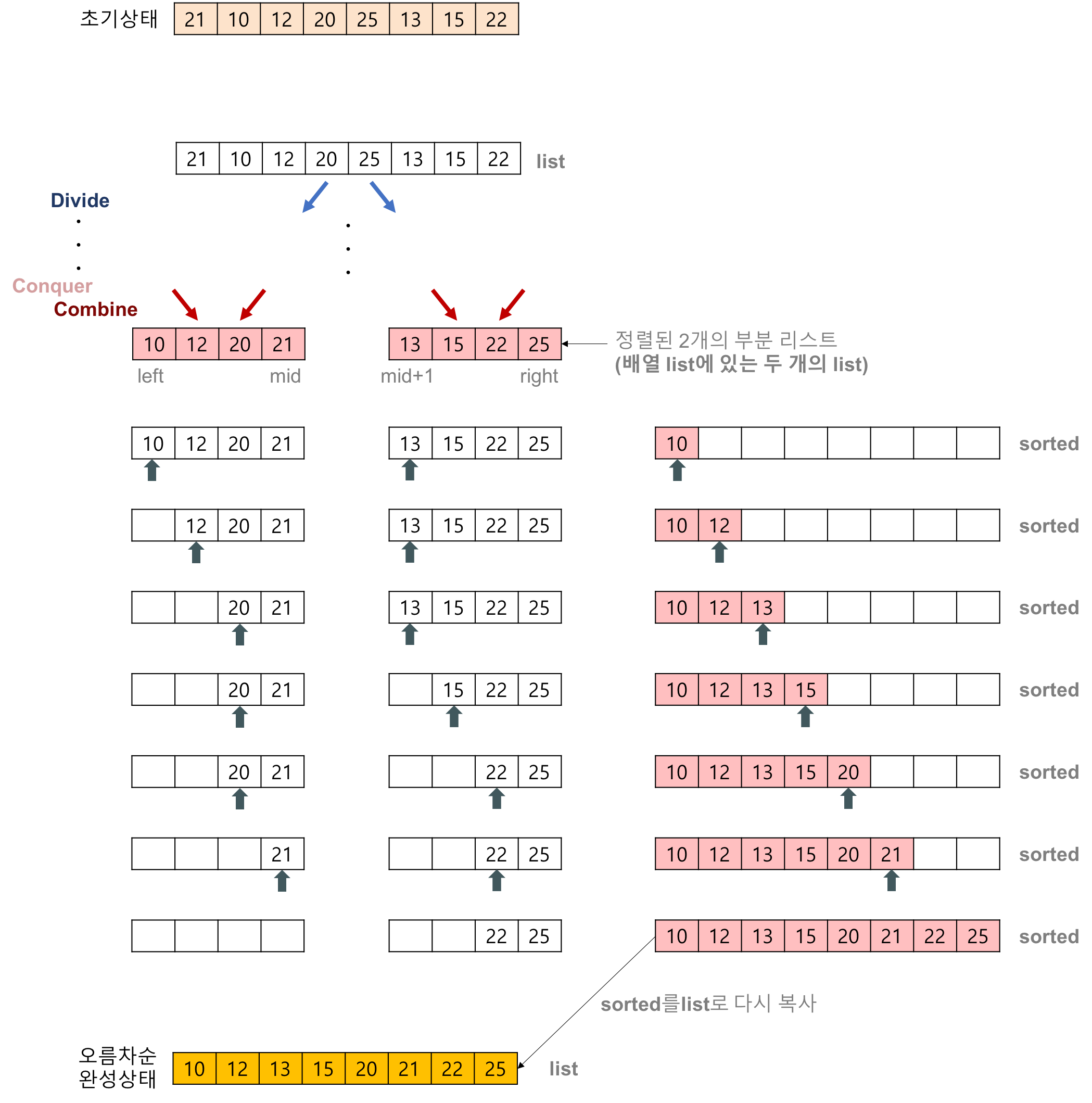
https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html ㉰ 힙 정렬 (Heap Sort)
- 힙 정렬은 정렬할 입력 레코드들로 힙을 구성하고 가장 큰 키값을 갖는 루트 노드를 제거하는 과정을 반복하여 정렬하는 알고리즘이다.
- 완전이진 트리(Complete Binary Tree)로 입력 자료의 레코드를 구성한다.
- 힙 정렬의 수행 시간은 다음과 같다.
최적 수행 시간 O(nlog2^n) 평균 수행 시간 O(nlog2^n) 최악 수행 시간 O(nlog2^n) 아래는 힙 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.
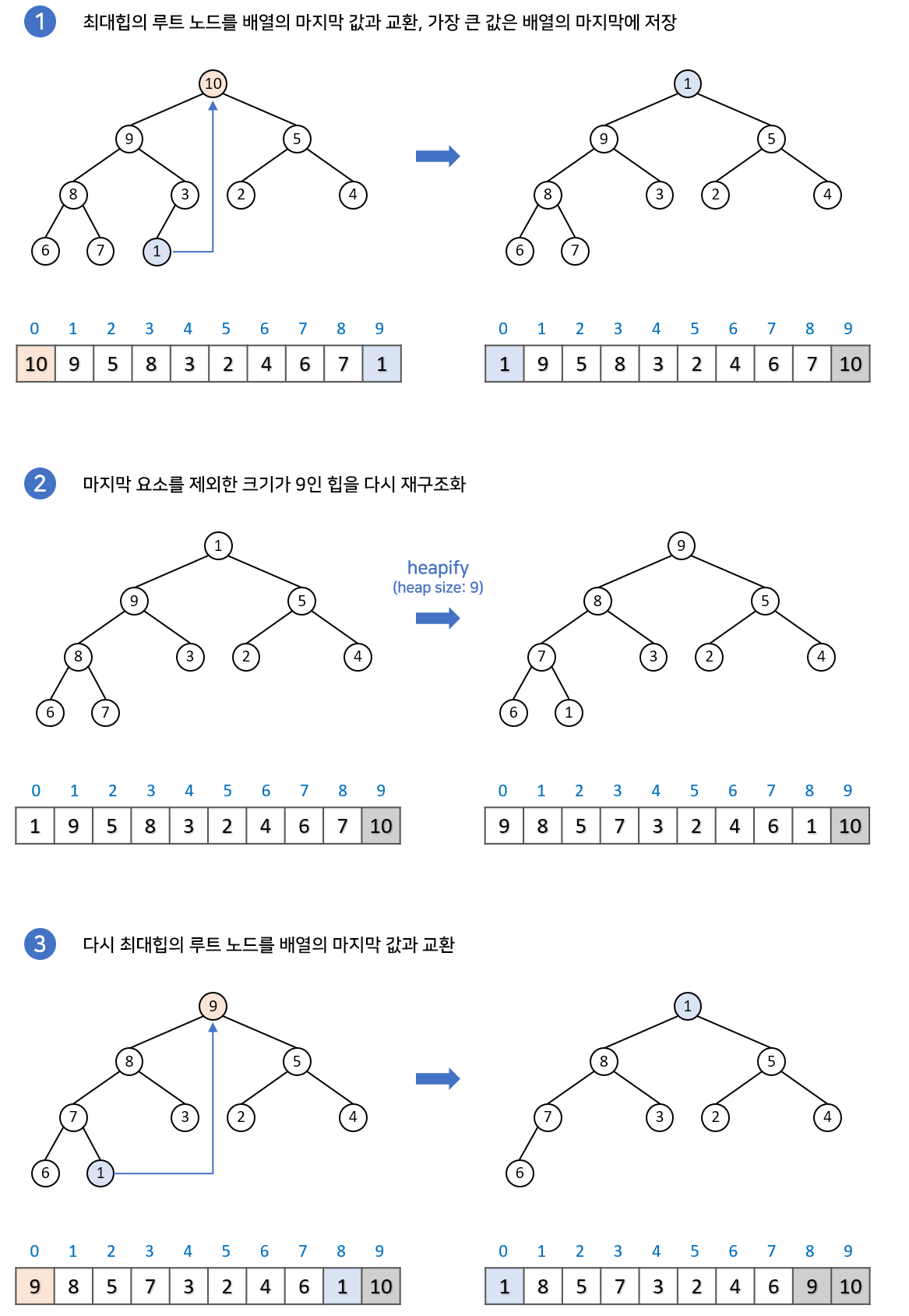
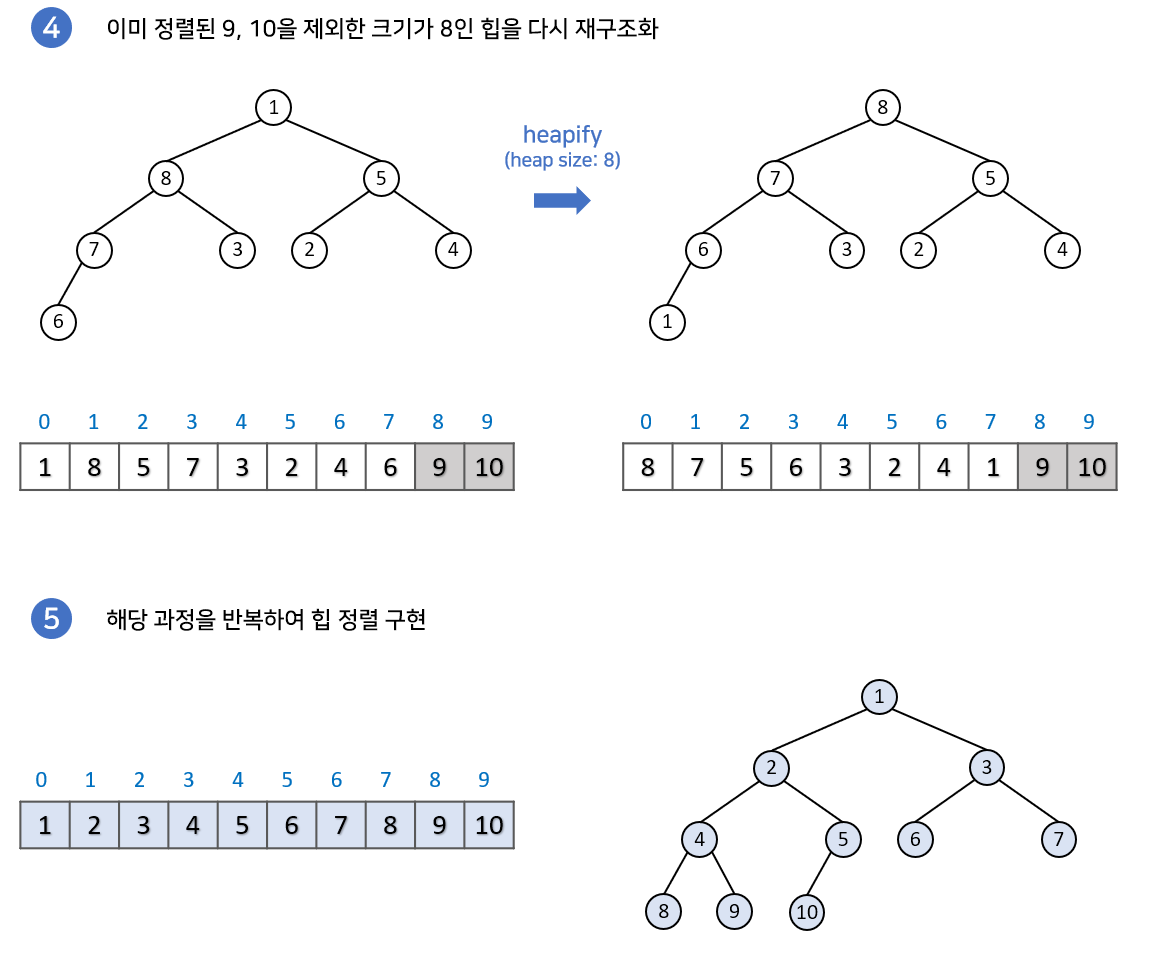
https://velog.io/@emplam27/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-%ED%9E%99%EC%A0%95%EB%A0%ACHeap-Sort ㉱ 거품 정렬 (Bubble Sort)
- 거품 정렬은 인접한 2개의 레코드 키값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 알고리즘이다.
- 두 인접한 원소를 교환하는 과정이 거품 모양과 같다고 하여 거품 정렬이라고 이름이 지어졌다.
- 한 PASS를 수행할 때마다 가장 큰 값이 맨 뒤로 이동하기 때문에, PASS를 '요소의 개수-1'번 수행하게 되면 모든 숫자가 정렬된다.
아래는 거품 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.
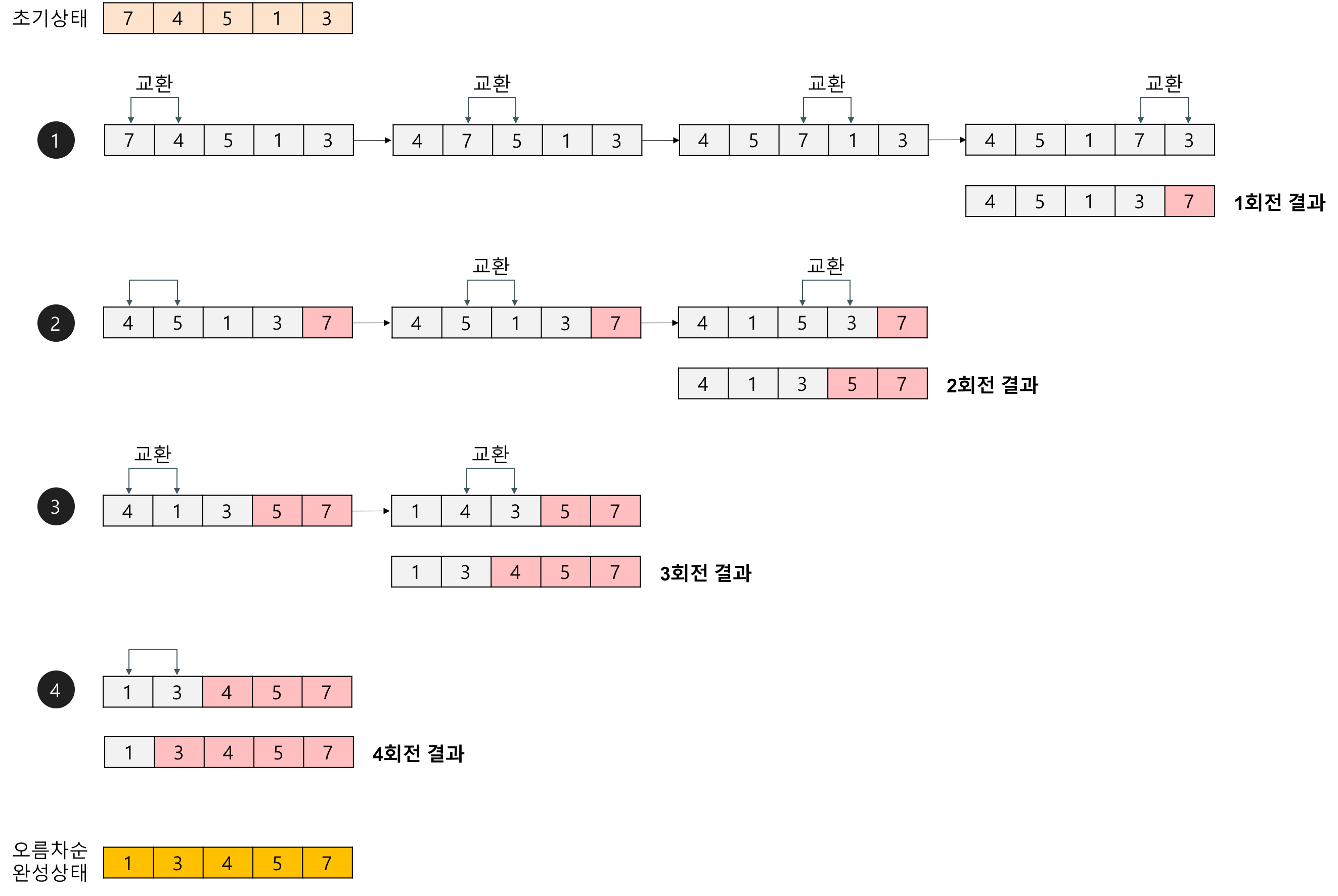
https://gmlwjd9405.github.io/2018/05/06/algorithm-bubble-sort.html ㉲ 삽입 정렬 (Insertion Sort)
- 삽입 정렬은 2번째 키와 첫 번째 키를 비교하여 순서대로 나열하고, 이어서 3번째 키를 1, 2번째 키와 비교해 순서대로 나열하고, 계속해서 n번째 키를 앞의 (n-1)개 키와 비교하여 알맞은 순서에 삽입하는 알고리즘이다.
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘이다.
아래는 삽입 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.

https://gmlwjd9405.github.io/2018/05/06/algorithm-insertion-sort.html ㉳ 선택 정렬 (Selection Sort)
- 선택 정렬은 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 정렬되지 않은 부분의 가장 앞의 데이터와 교환해나가는 알고리즘이다.
아래는 선택 정렬의 구체적인 실행이 어떻게 이뤄지는지 보여준다.
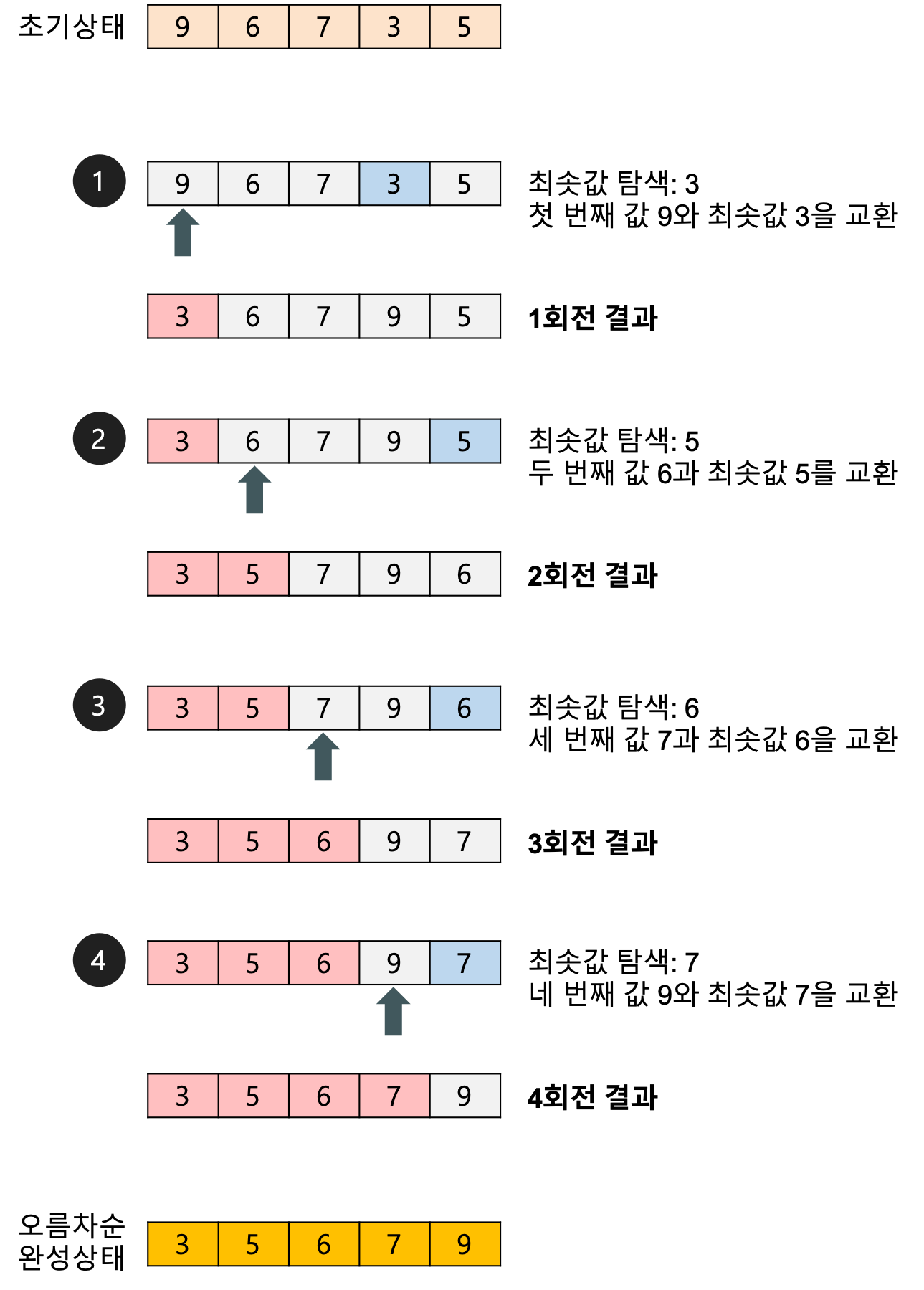
https://gmlwjd9405.github.io/2018/05/06/algorithm-selection-sort.html Reference
2022 수제비 정보처리기사 필기 1권+2권 합본세트 - 전2권
IT 비전공자를 위해 만들어진 수험서다. IT 분야의 최고 전문가 집단의 오랜 연구를 통한 정보처리기사 합격까지의 최단기 솔루션을 제안한다. 중요도에 따른 별점 체크, 두음쌤을 통한 암기비법
www.aladin.co.kr
반응형'CS > 정보처리기사' 카테고리의 다른 글
[정보처리기사 실기] 과목4 - 통합 구현, 오답노트 (0) 2023.07.09 [정보처리기사 실기] 과목3 - 데이터 입출력 구현, 오답노트 (0) 2023.07.06 [정보처리기사 실기] 과목2 - 화면 설계, 오답노트 (0) 2023.07.04 [정보처리기사 실기] 과목1 - 요구사항 확인, 오답노트 (0) 2023.07.03 [정보처리기사 필기] 자료 구조 (Data Structure) (0) 2023.06.29